Machine Learning
Autonomous driving, virtual assistants, image recognition, fraud checking, text summarization ... There are numerous applications of machine learning – an approach to artificial intelligence, where the program improves through experience over time. It learns.
To get a feeling for how machine learning differs from other approaches to AI, we want to take a look at a little game called Hexapawn. Hexapawn is a minified version of chess that has a 3x3 grid and all figures behave like pawns, i.e. they can move forward and capture diagonally. You will play the monkeys, while the computer will take care of the robots.
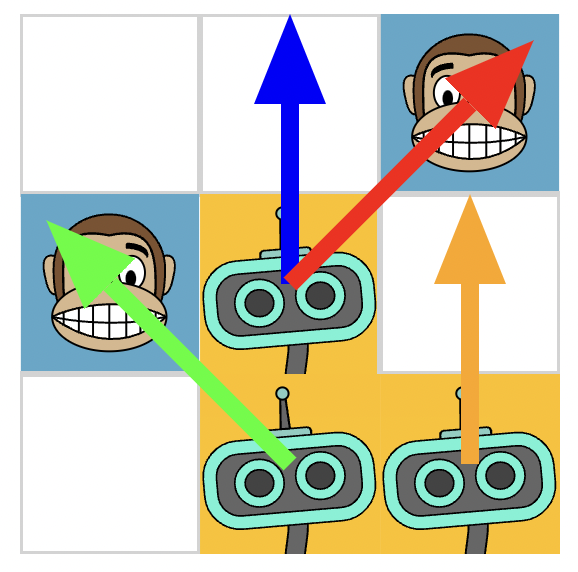
In this situation, there are four allowed moves for the robots.
Giving the computer a strategy
In a first step, we want to make the computer being able to play this game by using our own knowledge.
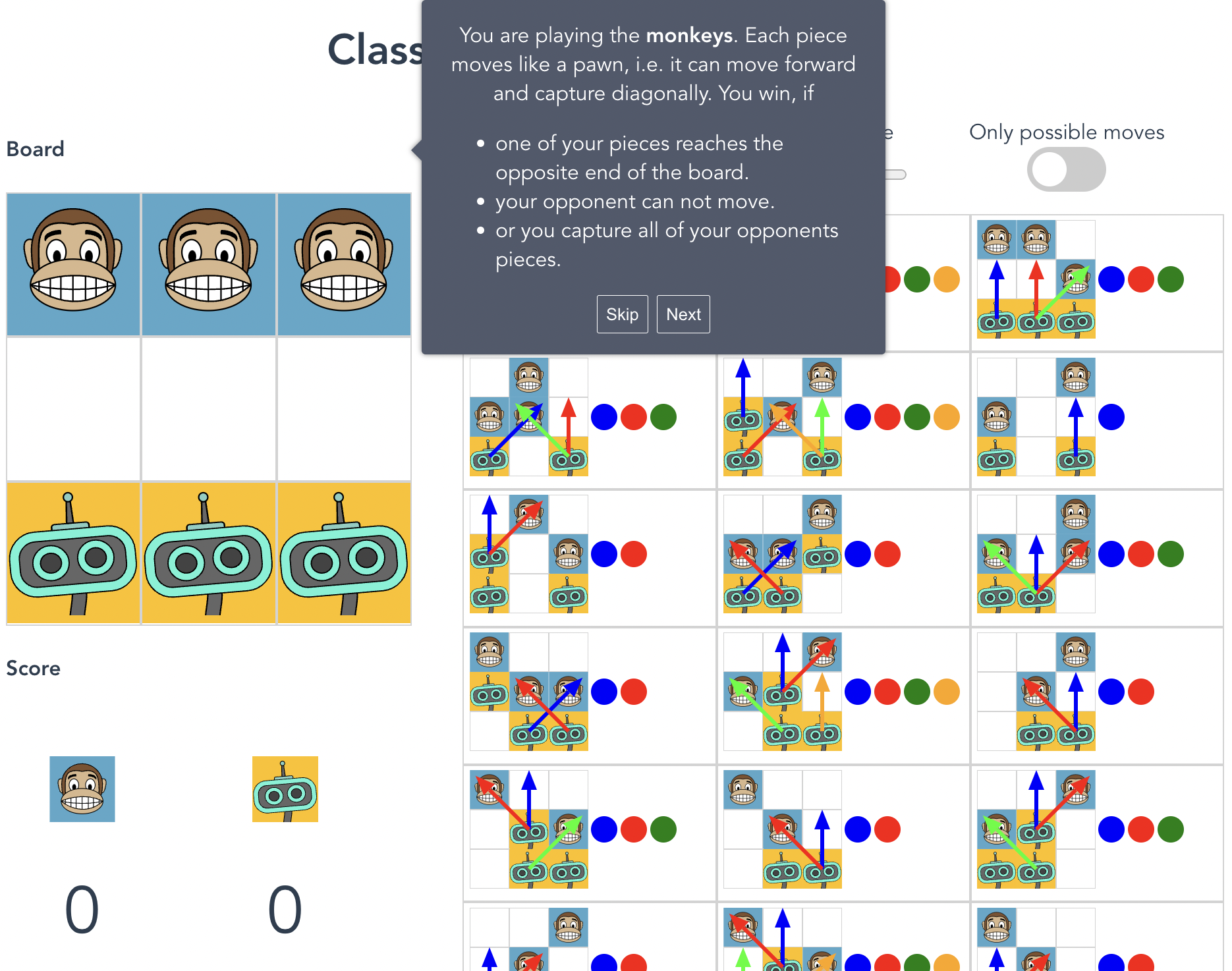
The game will allow you to specify a move for each situation by clicking on one of the colored tokens.
Letting the computer learn the strategy itself
Of course, there was no learning involved in the step above. We essentially defined the best move in each situation. However, for a lot of situations, it is pretty hard to define how the perfect strategy looks like, or how a dog looks like on the image with clear and precise rules. That's why, we look into machine learning next. For this, we will use the same game, but let the computer learn how to play the game itself.
-
A
A programmer has specified the best action for the agent in a given state. If it follows their recommendation, it is rewarded.
-
B
The computer receives instructions on how to behave in a particular state.
-
C
The computer receives a reward or punishment at certain points in time and thus learns to assess what value an action has in a certain state.
Correct! The computer receives a reward (adding colored tokens) or punishment (taking away the tokens) and thus learns to assess what value an action has in a certain state. This is one of the ways computers can learn.
Not quite! The computer receives a reward (adding colored tokens) or punishment (taking away colored tokens) and thus learns to assess what value an action has in a certain state. This is one of the ways computers can learn.
Answer the question to continue ...
At first, the computer will have little chance of winning, since it chooses its moves randomly (by drawing a token). The more games the computer finishes, the better it gets: it “learns” which moves will help it win and which it should avoid because they ended in defeat in the past. In this way, the computer’s strategy is gradually refined. Since the computer is punished for losing and rewarded for winning, we also call this way of learning reinforcement learning — learning by reward and punishment:
- Punishment: taking away a token in a move that led to defeat.
- Reward: adding a token to a move that led to a win.
This procedure eliminate moves that resulted in defeat, so that eventually only “good” moves remain. In practice, strategies that do not lead to success would not be eliminated immediately, but only the probability of their occurrence would be reduced. Thus, the AI gradually learns which strategy to apply in which situation, but does not instantly eliminate strategies that did not lead to success in the first try. Using reinforcement learning a computer can learn to win a game simply by knowing the rules of the game or possible inputs. Of course, reinforcement learning is not limited to games, it can be also applied to learn other strategies such as controlling the air condition in big buildings.
Similiar ideas of a computer program learning through experience over time can then be applied to all kinds of problems to derive decision rules, behavior or patterns. But these problems tend to have one thing in common. They need to process large amounts of data to figure out a connection between the input (a game situation or an image) and the desired output (an action or an answer to what is visible on the image). Depending on the problem, learning can take days, months or years in compute time.
Doing machine learning using a quantum computer
Essentially in machine learning, the computer learns about specific parameters. These can be the number of red, blue, green or yellow dots in our hexapawn game. But this can also be the rotations of gates in a quantum circuit. This is one way to do quantum machine learning. Quantum machine learning is an active field of research, so we expect new approaches popping up in the future.
One area where QML is definitely ahead is when we look problems where the data itself is of quantum rather than classical nature. Then a quantum computer is here to shine as recently demonstrated by researchers in an experiment that analyzed quantum data from the physical world.
In our project QLINDA, we investigate together with partners how reinforcement learning can help maximize performance in process manufacturing, or optimize production planning.